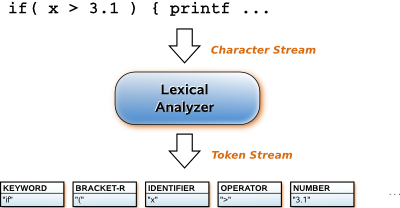
Lexical analysis is the process of converting an input stream of characters into a stream of words or tokens, which are groups of characters with collective significance. It is the first stage of automatic indexing and query processing:
- Automatic indexing, which is the process of algorithmically examining information items to generate lists of index terms. The lexical analysis phase produces candidate index terms that may be further processed, and eventually added to indexes.
- Query processing, which is the activity of analyzing a query and comparing it to indexes to find relevant items. Lexical analysis of a query produces tokens that are parsed and turned into an internal representation suitable for comparison with indexes.
| Lexical analysis for information retrieval systems is the same as lexical analysis for other text processing systems; in particular, it is the same as lexical analysis for program translators. There are three ways to implement a lexical analyzer: |
|
- Using a lexical analyzer generator, like the UNIX tool lex
- This approach is best when the lexical analyzer is complicated; if the lexical analyzer is simple, it is usually easier to implement it by hand.
- Writing a lexical analyzer by hand ad hoc
- An ad hoc algorithm, written just for the problem at hand in whatever way the programmer can think to do it, is likely to contain subtle errors.
- Writing a lexical analyzer by hand as a finite state machine
- Finite state machine algorithms are extremely fast, so ad hoc algorithms are likely to be less efficient.
|
Take your time (don’t hurry) on the exam. You do’nt get a bonus for finishing quickly. |