| If one considers a magazine article to be a document, then an issue of the magazine constitutes a corpus—it is a collection of one or more documents. |
|
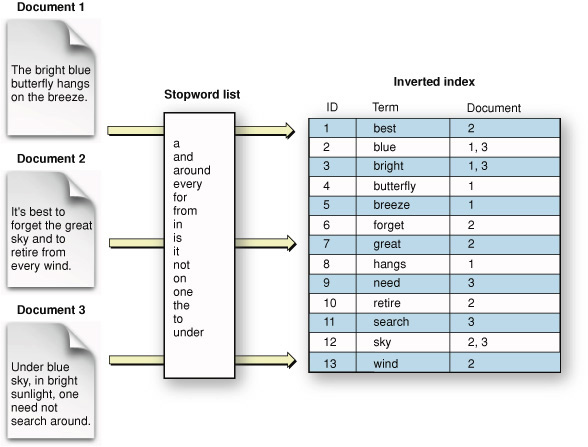
An index maps the salient information in a corpus into a format designed to let you quickly locate specific content. Each entry in an index points you to one or more articles. You can think of an index as a list of terms, with each term followed by a list of the documents it appears in.
| This sort of index, the one that people usually think of, is formally known as an inverted index. |
|
The term “inverted” refers to the arrangement of information in the index, which is intended to locate documents by matching on terms. This is “inverted” compared to using documents directly: if you pick up a book, you “match” on the document and “locate” all the terms in it.
|
“There are no ordinary moments.” ― Dan Millman, Way of the Peaceful Warrior: A Book That Changes Lives |