|
Sklearn is a free Python library that provides a wide range of unsupervised and supervised machine learning algorithms. |
|
It features various classification, regression and clustering algorithms including support-vector machines, random forests, gradient boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.
What Is Sklearn Used for?
The Sklearn Library is mainly used for modeling data and it provides efficient tools that are easy to use for any kind of predictive data analysis. The main use cases of this library can be categorized into six categories: (i) preprocessing, (ii) regression, (iii) classification, (iv) clustering, (v) model selection, and (vi) dimensionality reduction.
Sklearn can be obtained in Python by using the pip install function:
|
|
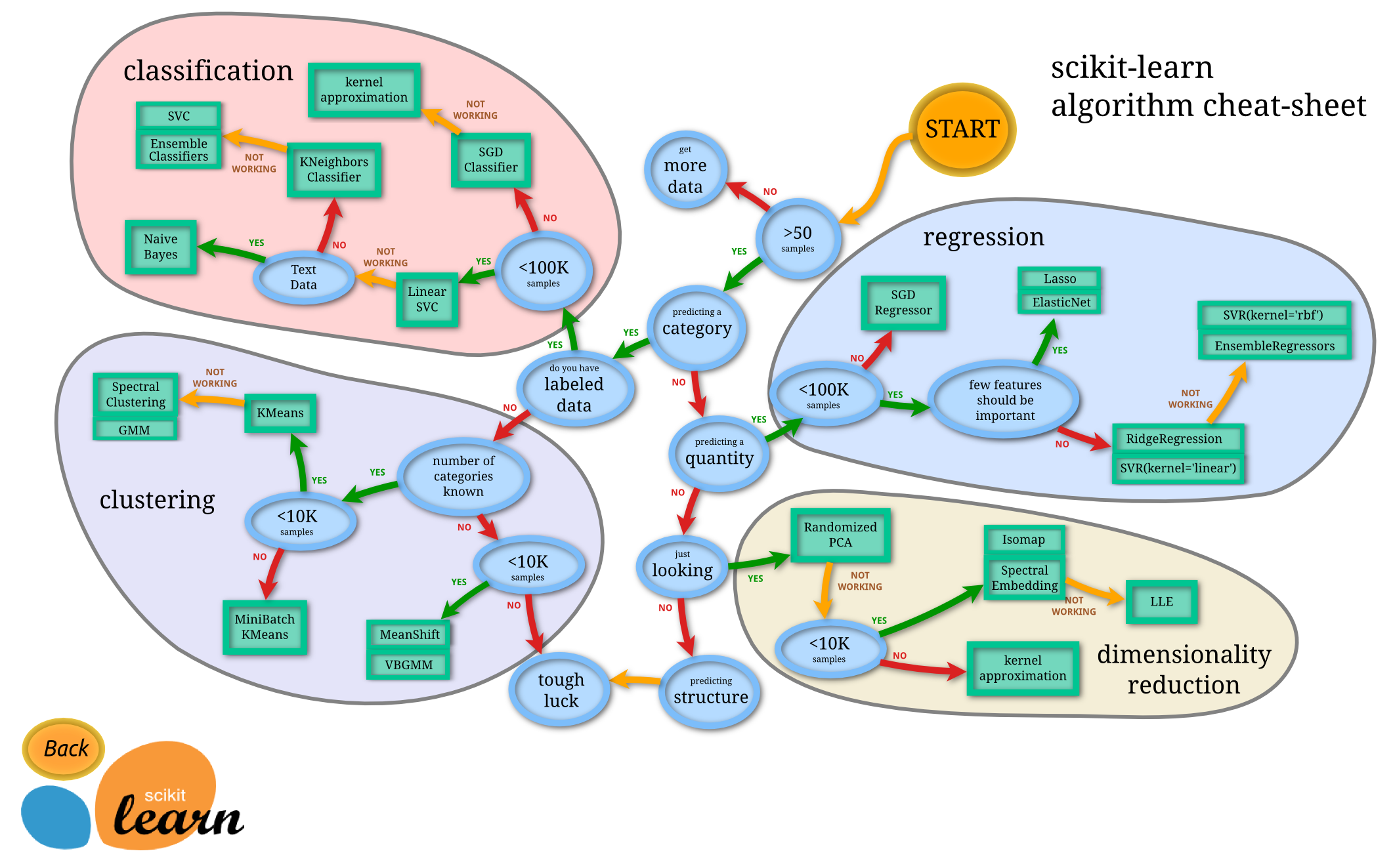
How to Pick the Best Sklearn Model?
When it comes to picking the best Sklearn model, there are many factors that come into play that range from experience and data to the problem scope and math behind each algorithm. Sometimes all chosen algorithms can have similar results and, depending on the problem setting, you will need to pick the one that is the fastest or the one that generalizes the best on big data. It may happen that all of your promised models won’t perform well enough and that you will simply need to combine multiple models (e.g. ensemble), make your own custom-made model.