There are several most popular decision tree algorithms such as
- ID3:
- ID3 (Iterative Dichotomiser 3) is the precursor to the C4.5 algorithm.
It can be summarized as follows:
- Take all unused attributes and count their entropy concerning test samples.
- Choose attribute for which entropy is minimum.
- Make node containing that attribute.
- C4.5:
- The decision trees generated by C4.5 can be used for classification, and for this reason, C4.5 is often referred to as a statistical classifier.
- C&RT (Classification and Regression Trees):
- In most general terms, the purpose of the analyses via tree-building algorithms is to determine a set of if-then logical (split) conditions that permit accurate prediction or classification of cases.
Here is an explanation on how a decision tree algorithm works.
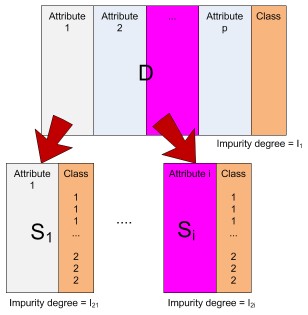
We have a data record which contains attributes and the associated classes.
Let us call this data as table D.
From table D, we take out each attribute and its associate classes.
If we have p attributes, then we will take out p subset of D.
Let us call these subsets as Si.
Table D is the parent of table Si.
|
|