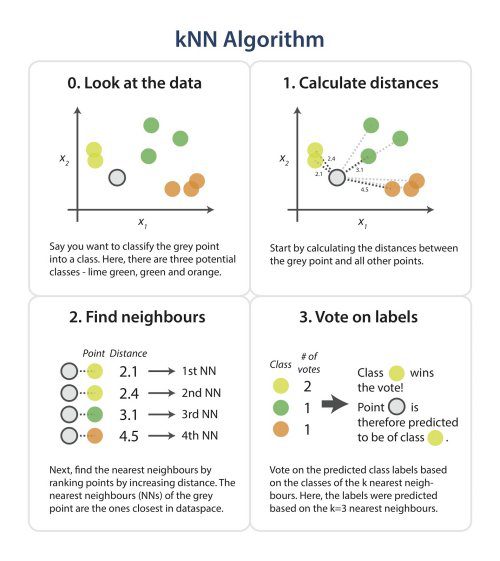
| The purpose of this kNN algorithm is to classify a new object based on attributes and training samples. Given a query point, we find K number of objects or (training points) closest to the query point. The classification is using majority vote among the classification of the K objects. Any ties can be broken at random. kNN used neighborhood classification as the prediction value of the new query instance. Notice the K in the figure should be 4 instead of 3. |
|
|
An Example of kNN Algorithm
We have data from the questionnaires survey and objective testing with two attributes (acid durability and strength) to classify whether a special paper tissue is good or not. Here are four training samples: |
|
| Now the factory produces a new paper tissue that passed laboratory test with X1=3 and X2=7 . Without another expensive survey, can we guess what the classification of this new tissue is? Fortunately, kNN algorithm can help you to predict this type of problem. |