This slide compares the average time between instructions of a single-cycle implementation to a pipelined implementation.
Serial Execution
In the single-cycle model, every instruction takes exactly one clock cycle, so the clock cycle must be stretched to accommodate the slowest instruction. From the previous table, the slowest instruction is
lw—so the time required for every instruction is 800 ps.
The following figure shows the single-cycle, nonpipelined execution using the hardware listed in the previous slide.
| The time between the first and fourth instructions in the nonpipelined design is 3×800 ps = 2400 ps. |
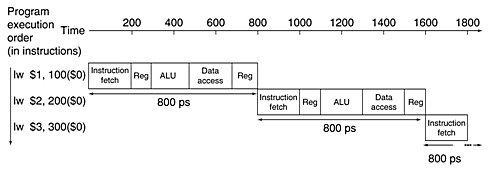
|
Pipelining
All the pipeline stages take a single clock cycle, so the clock cycle must be long enough to accommodate the slowest operation. Just as the single-cycle design must take the worst-case clock cycle of 800 ps, the pipelined execution clock cycle must have the worst-case clock cycle of 200 ps, even though some stages take 100 ps. The following figure shows the corresponding pipelined execution.
| It offers a fourfold performance improvement: the time between the first and fourth instructions is 3×200 = 600 ps. |
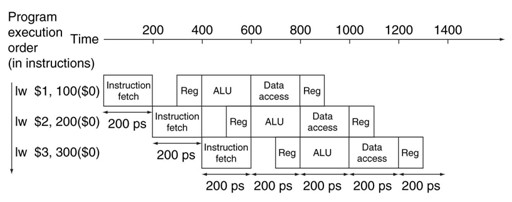
|